Avaliação da qualidade das amostras usando SOM clustering¶
Prática com R Notebook¶
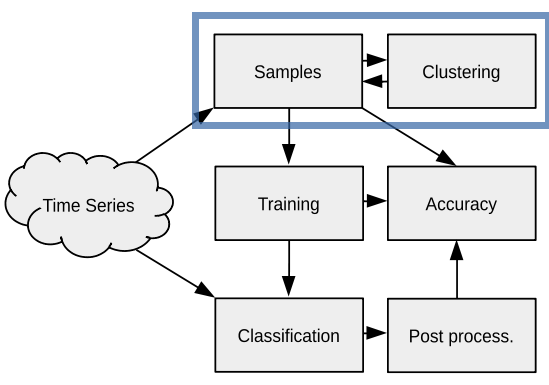
Neste hands-on, organizamos uma atividade prática no sits de acordo com o fluxograma apresentado ao lado. Nele, mostramos como é realizada a avaliação de amostras no sits. Aqui você aprenderá a:
realizar a análise de clustering utilizando o SOM.
obter um conjunto de amostras de melhor qualidade.
Notebook Kaggle: https://www.kaggle.com/lorenalves01/clustering-worcap/
Introdução¶
Um dos desafios chave quando utilizamos amostras para treinar modelos de classificação supervisonada é avaliar a qualidade do modelo gerado. Um conjunto de amostras ruidoso e imperfeito pode causar um efeito negativo no desempenho da classificação (Frenay et al., 2013). Aplicar um método de pré-processamento para melhoria da qualidade das amostras, onde a remoção de dados que foram rotulados erroneamente ou que tenha baixo poder discriminatório, pode influenciar na geração de mapas classificados mais acurados. Neste módulo será abordado o problema de detecção de ruído de classe e melhoria da qualidade de um conjunto de dados de séries temporais de imagem de satélite utilizando como abordagem principal o método de agrupamento de mapas auto-organizáveis, em inglês Self-Organzing Maps (SOM).
Efeitos de ruído de classe na classificação¶
Para ilustrar os efeitos que um conjunto de amostras com qualidade ruim pode causar na geração de um modelo de aprendizado de máquina, apresentamos o exemplo da Figura 78, onde a classificação de uma série temporal de uso e cobertura da terra ao longo de 16 anos foi realizada. O conjunto de dados utilizado para treinamento do modelo random forest possui amostras que foram rotuladas de forma errônea.
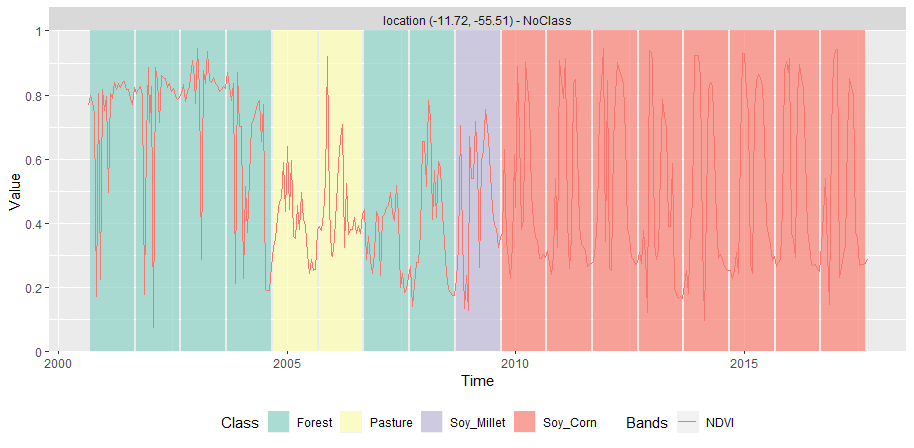
Figure 78 - Resultado de uma classificação ruim de uma série temporal utilizando o método random forest.¶
Na classificação gerada pelo modelo random forest, na Figura 78, uma inconsistência é apresentada durante a trajetória da classificação apresentando o anos de 2007 e 2008 classificados como floresta logo em seguida de pasto. Dado que em um ano uma floresta não se regenera, podemos notar a presença de um erro na classificação da série temporal para estes anos. Isto se deve ao fato de possuir amostras que deveriam ter sido rotuladas como pasto ou alum tipo de agricultura, no entanto elas foram rotuladas como floresta.
A Figura 79 apresenta a classificação da mesma série temporal apresentada anteriormente, porém houve um pré-processamento no conjunto de dados utilizado para treinar o modelo do random forest para a remoção de ruídos de clases.
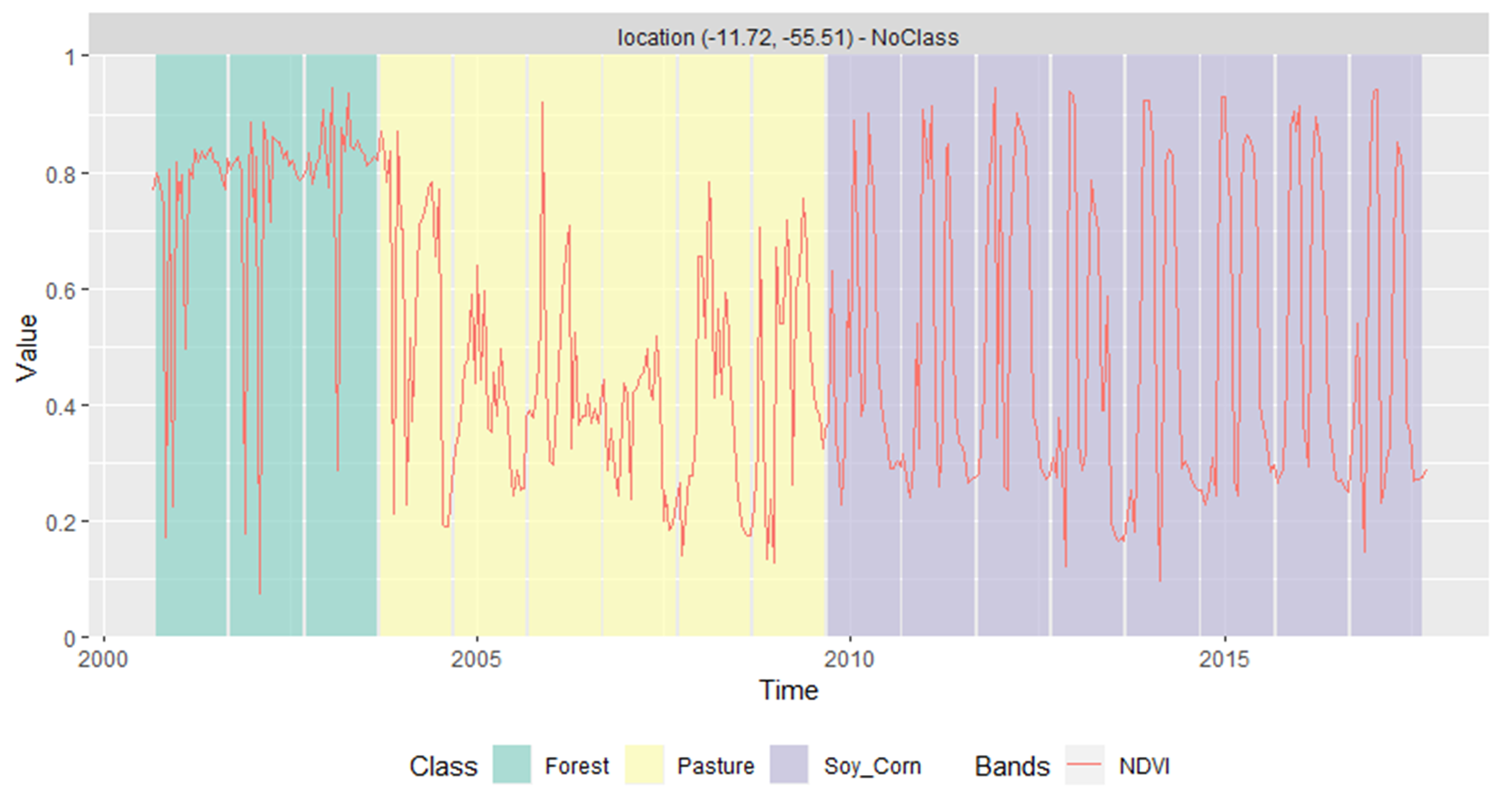
Figure 79 - Classificação da mesma série temporal após a remoção de amostras ruidosas.¶
O metódo SOM no contexto do projeto Brazil Data Cube é utilizado para avaliar a qualidade e a remoção de cada uma das amostras do conjunto de dados de treinamento.
Método SOM para identificação de ruído de classe¶
O método SOM é uma rede neural não supervisionada que mapeia um conjunto de dados de alta dimensionalidade em um de baixa dimensionalidade, geralmente uma grade bi-dimensional. A Figura 80 apresenta a estrutura da rede SOM. O espaço de saída da rede é composta por unidades chamadas neurônios. Cada neurônio possui um vetor de pesos associados a ele, onde cada vetor de peso possui a mesma dimensão que o dado de entrada. Geralmente, a inicialização do método pode ser realizada de forma aleatória e então a rede é treinada através de aprendizado competitivo. A ideia principal do SOM é calcular a distância entre cada amostra do conjunto de dados e todos os neurônios afim/a fim de encontrar o neurônio que possui a menor distância. O neurônio que possui a menor distância é chamado de melhor unidade de medida em inglês Best matching unit (BMU). O peso de uma BMU e de seus vizinhos devem ser atualizados para que similaridade da vizinhança dos neurônios prevaleça Kohonen et al. (2001).
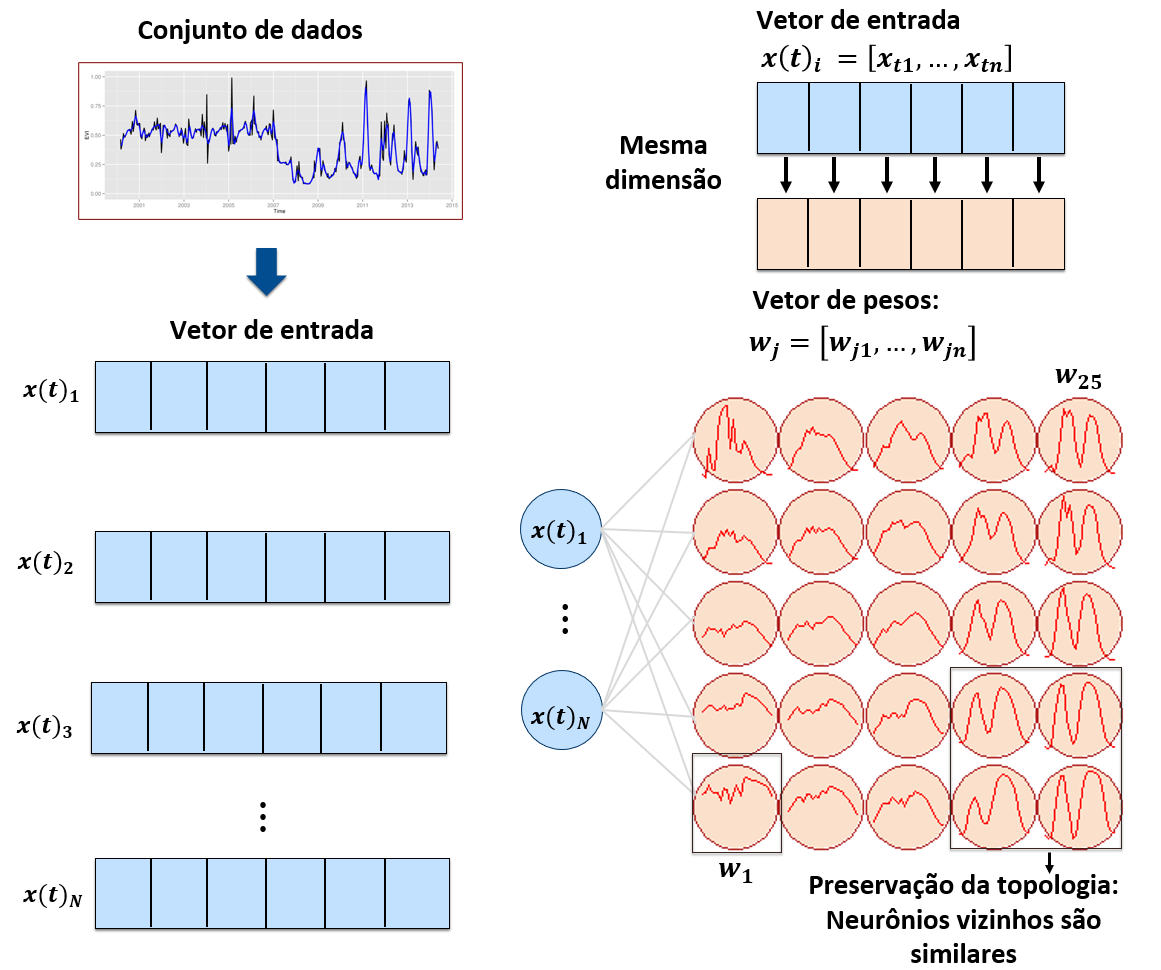
Figure 80 - Estrutura da rede SOM. Fonte: (Santos et al, 2020).¶
Após o treinamento da rede SOM, cada amostra está associada a neurônio, portanto os neurônios podem ser rotulados a partir da técnica de voto majoritário Assim o mapa SOM é usado para avaliar a qualidade de cada elemento do conjunto de treinamento. Cada neurônio será associado a uma distribuição de probabilidade discreta, a qual denominamos probabilidade condicional. Neurônios mais homogêneos, aqueles com uma única classe de alta probabilidade, são compostos por amostras de boa qualidade. Neurônios heterogêneos, aqueles com duas ou mais classes com probabilidade significativa, provavelmente contêm amostras ruidosas. Além disso consideramos que a probabilidade da classe de neurônios (probabilidade condicional) não é a melhor medida de ruído de classe porque os vizinhos de cada neurônio de um mapa SOM fornecem informações adicionais sobre a variabilidade intraclasse e interclasse. Portanto, aplicamos a inferência bayesiana às vizinhanças do mapa SOM para melhorar a avaliação da qualidade de cada série temporal, chamamos a probabilidade que sofre influência dos neurônios vizinhos de probabilidade posterior. Na Figura 81 o neurônio 3 pertence a Classe 2 porque 75% das amostras que foram associadas a este neurônio pertecem a Classe 2. No entanto, todos os neurônios vizinhos pertecem a Classe 1, isto influência na confiabilidade das amostras associadas ao neurônio 3, fazendo com que a probabilidade posterior seja menor que condicional.
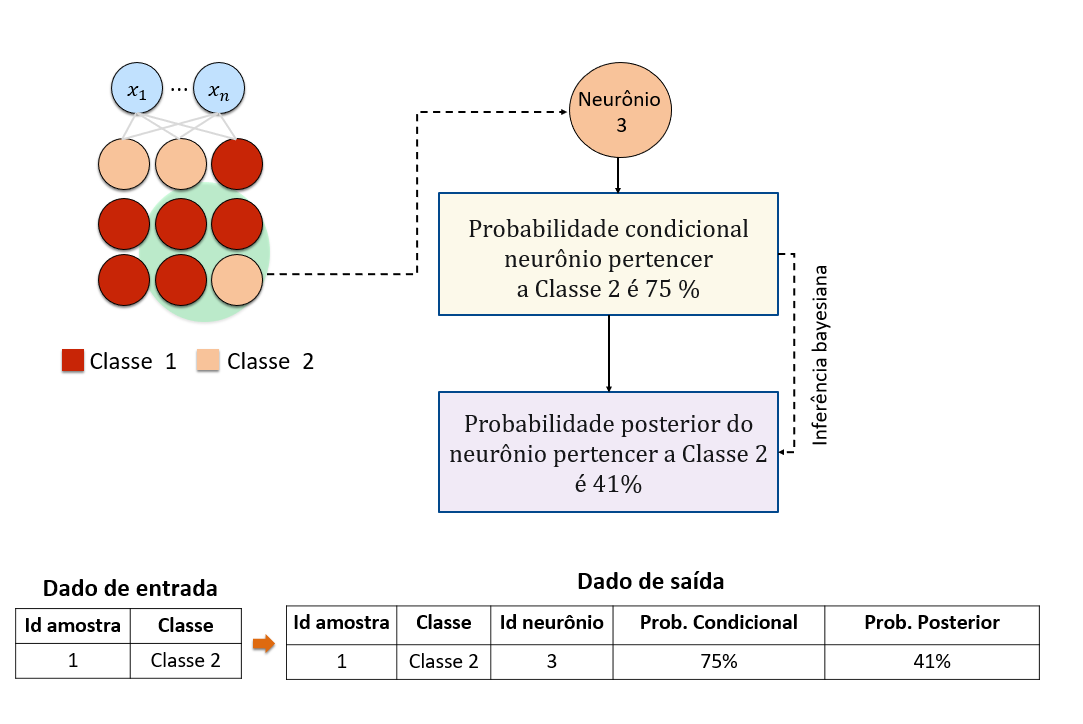
Figure 81 - Aplicando a inferência bayesiana no neurônio 3¶
A tabela abaixo apresenta um exemplo da saída do método de qualidade de amostras. As probabilidades condicional e posterior indicam o nível de confiabilidade delas realmente pertecerem a classe pasto dado o neurônio onde elas foram alocadas e a sua vizinhança.
Id amostra |
Classe |
Prob. Condicional |
Prob. Posterior |
1 |
Pasto |
100% |
99.9% |
2 |
Pasto |
38% |
33% |
3 |
Pasto |
70% |
20% |
Para determinar se a amostra deve ser removida, mantida ou analisada, as probabilidades devem ser analisadas em conjunto. A Figura 82 apresenta um fluxograma que indica qual decisão será tomada a partir dos limiares definidos para definir a qualidade do conjunto de amostras.
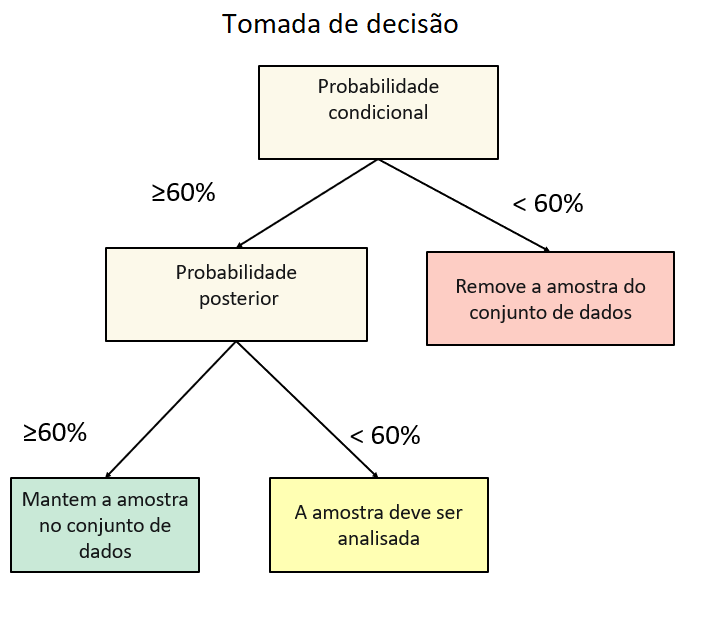
Figure 82 - Fluxogama de tomada de decisão.¶
Utilizando as amostras que foram ilustradas na tabela acima e os limiares apresentados na Figura 82, a amostra 1 deve ser mantida conjunto de dados, a amostra 2 é automaticamente removida do conjuntos de dados, e a amostra 3 deve ser avalidada por especialistas para verificar se elas devem ser mantidas ou não conjunto de dados.
Devida a alta probabilidade condicional da amostra 3, a primeira hipótese é que um subconjunto de amostras de pasto pode conter padrões diferentes dos demais, portanto, este subconjunto pode está mapeado longe de sua vizinhança do espaço de atributos do SOM, sendo assim, essas amostras devem ser mantidas no conjunto de dados. A segunda hipótese é que este subconjunto de dados pode ruído de classe, logo, estas amostras devem ser removidas do conjunto de dados.
Referências¶
Frénay, B., and Verleysen, M. Classification in the presence of label noise: a survey. IEEE transactions on neural networks and learning systems, 25(5):845–869, (2013).
Kohonen,T., Schroeder M. R., and Huang, T. S. Self-Organizing Maps. Springer-Verlag New York, Inc., Secaucus, NJ, USA, 3rd edition, 2001.
Santos, Lorena A., et al. “Clustering Methods to Asses Land Cover Samples of MODIS Vegetation Indexes Time Series.” International Conference on Computational Science and Its Applications. Springer, Cham, 2017.
Santos, Lorena A., et al. “Quality control and class noise reduction of satellite image time series”. Manuscript submitted to ISPRS Journal of Photogrammetry and Remote Sensing, July, 2020.