Introdução a séries temporais de imagens de satélites¶
Introdução¶
Ao longo das últimas décadas, presenciamos um aumento significativo de lançamentos de plataformas orbitais para fins de observação da terra (Finer et al., 2018). Esse crescente interesse está relacionado com a capacidade de monitorar diversos aspectos da superfície do planeta e de sua biodiversidade.
Hoje, a observação da terra é um dos meios mais efetivos e consistentes para esse tipo de monitoramento, pois é possível recobrir grandes áreas e obter imagens de um mesmo local ao longo do tempo (Picoli et al., 2018).
Uma aplicação direta das imagens de sensores orbitais é o mapeamento de uso e cobertura da terra, que é um importante instrumento para apoiar políticas públicas e medir taxas de emissão de gases de efeito estufa (Simoes et al., 2020).
Existem muitas técnicas de mapeamento de uso e cobertura da terra. Aqui, nos vamos nos concentrar numa abordagem específica de mapeamento usando séries temporais. As séries temporais são obtidas a partir do arranjo sistemático de imagens de diferentes datas de observação.
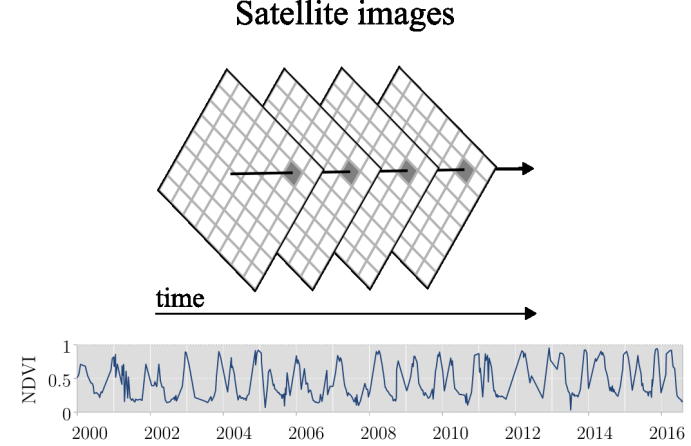
Figure 73 - Satellite Image Time Series¶
Perfil espectro-temporal de uso e cobertura da terra¶
Uma hipótese fundamental da abordagem de mapeamento de uso e cobertura da terra usando séries temporais é a de que cada classe de uso e cobertura está associada a um comportamento espectral específico no tempo. Na figura abaixo, podemos observar diferentes comportamentos nas séries temporais de NDVI para cada classe de uso e cobertura da terra.
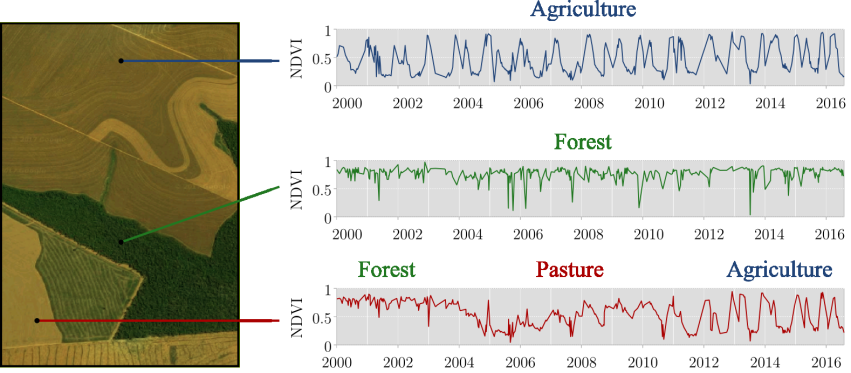
Figure 74 - Trajetória da terra. Fonte: Victor Maus¶
Mudanças de classes de cobertura ao longo do tempo devido a diferentes usos da terra podem ser capturadas por mudanças nos perfis das séries temporais. Ao conjunto dessas mudanças de classes denominamos trajetória de uso e cobertura da terra.
Mapeamento de uso e cobertura da terra¶
Uso de machine learning para o mapeamento de uso e cobertura da terra permite delegar a detecção dos padrões relevantes da série temporal de cada classe para um algoritmo a partir de amostras previamente conhecidas. Para melhor entender esse processo, podemos citar outras duas abordagens de classificação de séries temporais, o TIMESAT e o TWDTW.
O TIMESAT é uma técnica que extrai atributos específicos (e.g. mínimos, máximos) das séries temporais para, a partir de tais atributos, realizar a classificação. O pressuposto é o de que alguns desses atributos podem ser mais importante que outros para diferenciar as classes umas das outras.
O TWDTW é uma técnica que identifica similaridades entre formas de séries temporais para realizar a classificação. O pressuposto é o de que a menor distância (i.e. distância DTW) entre duas séries temporais determine a classe de uso e cobertura. Na prática, leves mudanças de alongamento, à esquerda ou à direita, da curva que representa a série temporal não deve influenciar significativamente a distância DTW.
Ao contrário dessas duas abordagens, o uso do machine learning não parte de pressupostos específicos para a identificação de padrões. O processo de aprendizado do algoritmo identificará aqueles atributos que melhor diferenciam uma classe da outra.
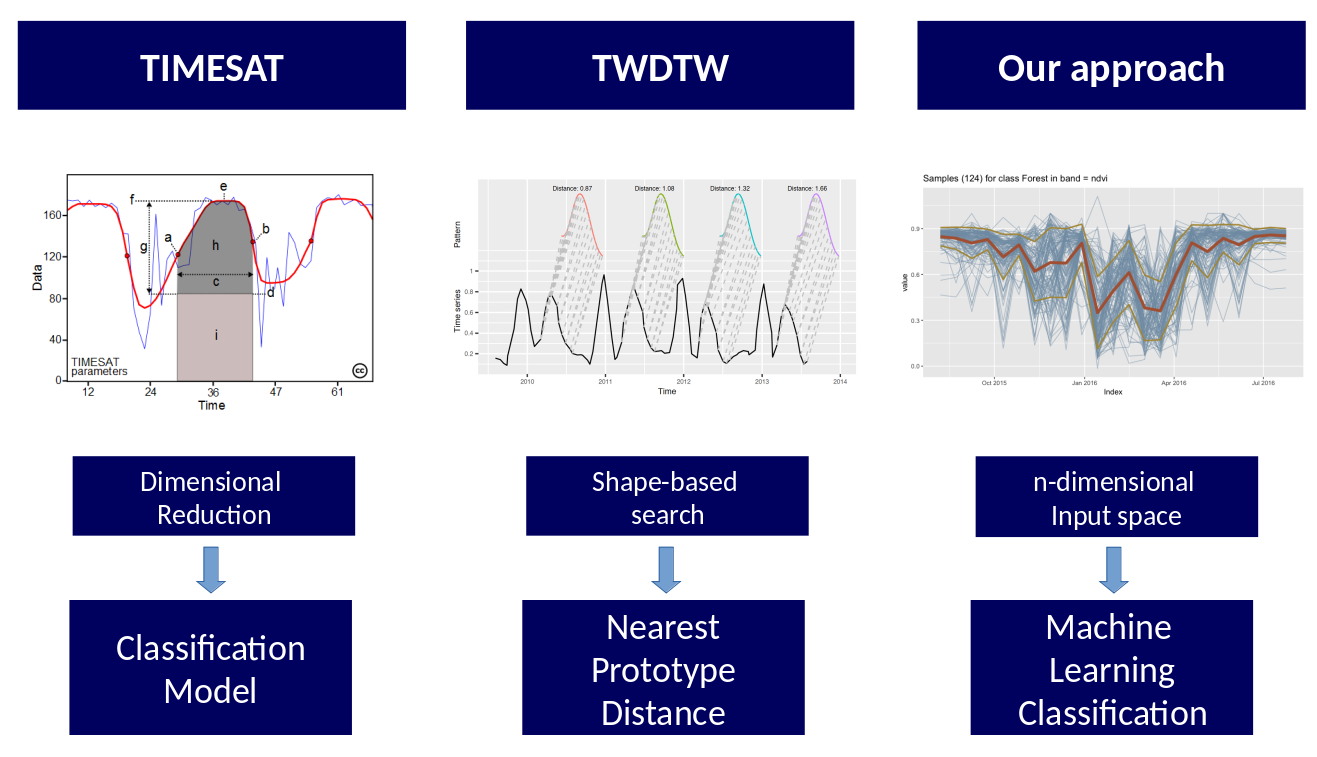
Figure 75 - Diferentes abordagens de classificação de séries temporais.¶
Pacote sits¶
O sits é um pacote desenvolvido na linguagem R para classificação de uso e cobertura da terra usando séries temporais. Seu código é aberto e pode ser acessado no GitHub <https://github.com/e-sensing/sits>. A figura a seguir apresenta um fluxograma resumido das tarefas propostas pelo pacote.
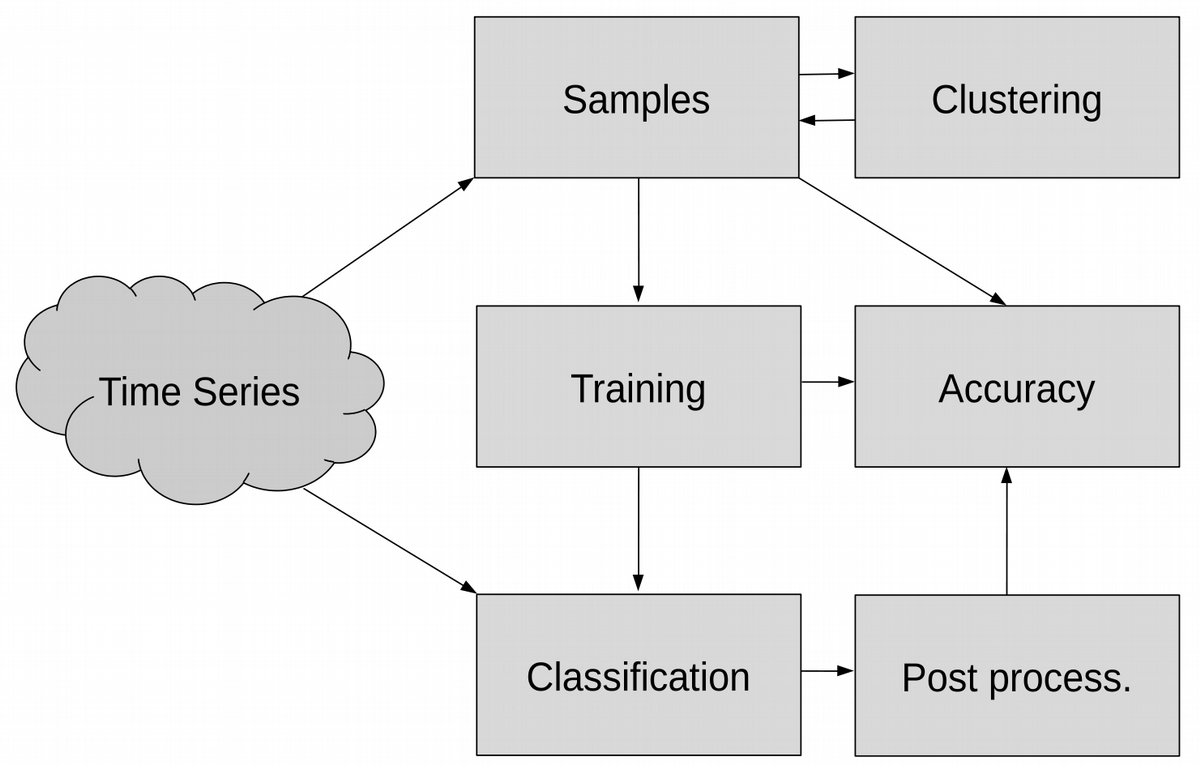
Figure 76 - Fluxo de trabalho do pacote sits.¶
Time series: representado no diagrama como uma nuvem, consiste em qualquer fonte de séries temporais de imagens de satélite, desde serviços Web, como WTSS (Queiroz et al., 2015) e SATVeg (Esquerdo et al., 2020), a arquivos na nuvem ou locais.
Samples: representa um conjunto de amostras de séries temporais necessárias para treinar ou validar um modelo de classificação.
Clustering: é uma ferramenta analítica das amostras. Permite realizar uma avaliação de qualidade e identificação de pureza em uma determinada classes de uso e cobertura da terra (Santos et al., 2017).
Training: é a etapa de treinamento do machine learning. Consiste, no pacote, de uma interface comum em que diversos algoritmos de aprendizado de máquina podem ser usados para gerar um classificador de uso e cobertura da terra.
Classification: representa o processo de aplicação do modelo treinado a séries temporais de classe desconhecida. A saída desse processo é um vetor de probabilidades associadas a cada uma das classes treinadas no modelo. Este procedimento pode ser aplicado a um conjunto esparso ou denso de séries temporais. No primeiro caso, um pequeno conjunto de séries temporais são classificadas e armazenadas em uma tabela. No segundo caso, as séries provenientes de um cubo de dados geram cubos de dados de probabilidades.
Accuracy: esta etapa consiste na avaliação do modelo ou mapas gerados pelo modelo. A avaliação consiste na estimação de acurácia tendo como base amostras de validação ou validação cruzada com as amostras de treinamento.
Post processing: O pós-processamento consiste na etapa de obtenção de mapas de uso e cobertura da terra a partir dos cubos de probabilidades gerados na classificação. Outras técnicas como suavização e análise de trajetórias (Maciel et al., 2019) podem ser usadas aqui.
O pacote sits fornece uma API de funções que permite o trânsito entre as etapas conectadas com as setas. As estruturas de dados consistem em basicamente três: 1) uma tabela de metadados de cubos/imagens ou de serviços Web que fornecem acesso a séries temporais; 2) uma tabela para armazenar metadados de amostras e suas respectivas séries temporais; e 3) um modelo de dados para guardar o classificador treinado.
Práticas com os R Notebooks¶
No que se segue, organizamos as atividades práticas de acordo com o fluxograma apresentado acima. No primeiro hands-on, mostramos como preparar o ambiente Kaggle e como instalar o pacote sits. No segundo hands-on, mostramos como é realizazdo o acesso a séries temporais usando o pacote sits. No terceiro, mostramos como treinar e classificar séries temporais esparças no sits. No quarto hands-on, apresentamos um método de avaliação de qualidade das amostras usando a técnica de self-organized maps. No quinto, mostramos como classificar um mapa a partir de séries temporais armazenadas em arquivos locais (bricks). Por fim, apresentamos como podemos avaliar o modelo e os mapas gerados.
Referências¶
Finer, Matt, et al. “Combating deforestation: From satellite to intervention.” Science 360.6395 (2018): 1303-1305.
Picoli, Michelle Cristina Araujo, et al. “Big earth observation time series analysis for monitoring Brazilian agriculture.” ISPRS journal of photogrammetry and remote sensing 145 (2018): 328-339.
Simoes, Rolf, et al. “Land use and cover maps for Mato Grosso State in Brazil from 2001 to 2017.” Scientific Data 7.1 (2020): 1-10.
Queiroz, Gilberto Ribeiro, et al. “WTSS: um serviço web para extração de séries temporais de imagens de sensoriamento remoto.” (2015).
Esquerdo, Júlio César Dalla Mora, et al. “SATVeg: A web-based tool for visualization of MODIS vegetation indices in South America.” Computers and Electronics in Agriculture 175 (2020): 105516.
Santos, Lorena A., et al. “Clustering Methods to Asses Land Cover Samples of MODIS Vegetation Indexes Time Series.” International Conference on Computational Science and Its Applications. Springer, Cham, 2017.
Maciel, Adeline Marinho, et al. “A spatiotemporal calculus for reasoning about land-use trajectories.” International Journal of Geographical Information Science 33.1 (2019): 176-192.